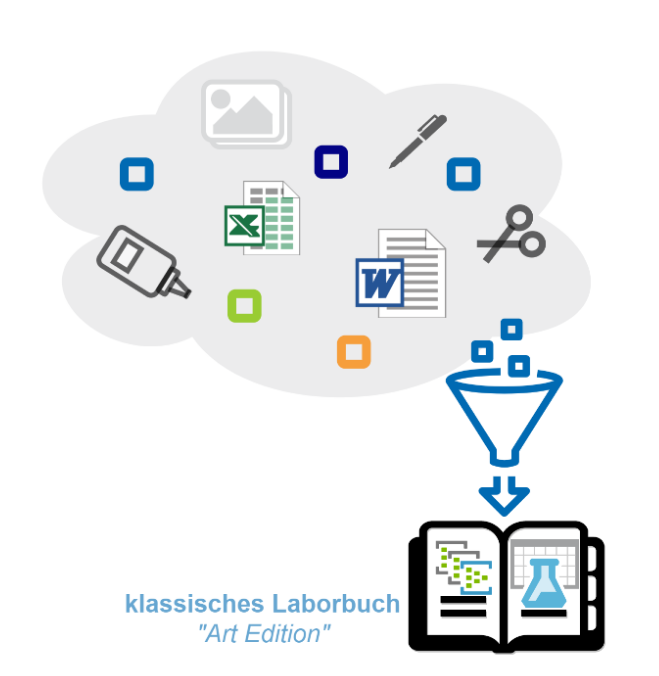
Die Diskussion um Künstliche Intelligenz (KI) in der Wissenschaft dreht sich oft um Modelle, Tools und Anwendungen. Die „AI Preparedness Guidelines for Archivists“ der Archives and Records Association UK lenken den Blick jedoch auf einen grundlegenderen Punkt: Die eigentliche Voraussetzung für KI ist die Qualität und Struktur der Daten selbst. Für das Forschungsdatenmanagement (FDM) und […]